Introduction¶
Why bother?¶
A graph is a data representation that can express entities (e.g., users and goods) and connections (e.g., purchases). Graph computation pairs for analyzing and querying graph data have been widely used in a large number of business scenarios, such as product recommendation, fraud detection, supply chain analysis, and so on.
However, in practice, the data is often stored in relational database management systems (RDBMS), and the graph data is generated from the relational data. The traditional way to analyze graph data is to extract the data from the relational database and migrate it to a graph database for graph computation.
There are two common architectures for graph data processing:
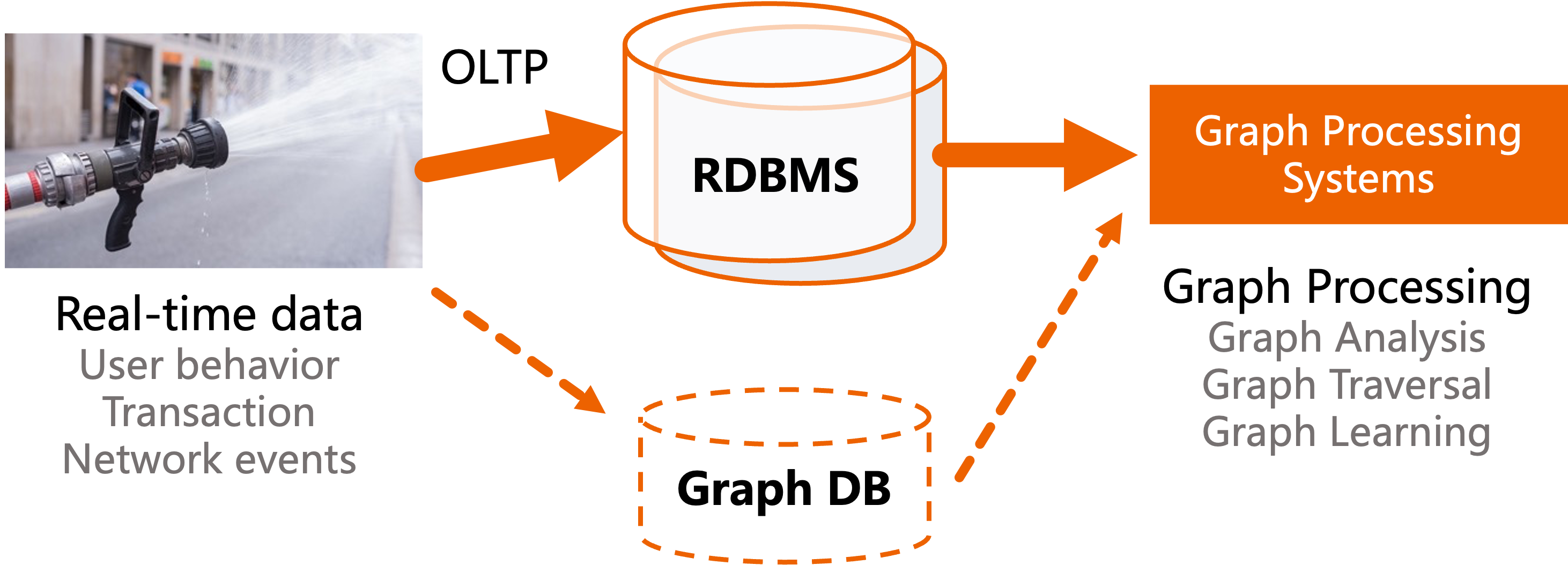
Common architectures for graph data processing¶
To do graph computation, relational database systems will provide some interface extensions, which are equivalent to a kind of syntactic sugar for graph computation, and the underlying still uses the relational model, e.g., GraphScript provided by SAP HANA, SQL Graph provided by SQL Server, Apache AGE as an extension for PostgreSQL.
On the other hand, there is also the option of exporting the data as offline graph data for offline graph data analysis and processing on a graph computation system (Neo4j, GraphScope, …).
An ideal model for processing online graph data needs to fulfill at least the following three requirements:
Performance. Storing data as tables in relational storage for graph computation requires a large number of time-consuming join operations. Such operations cause serious performance degradation compared to the graph native storage and execution engine.
Data freshness. To keep the data consistent, long offline data moves need to be avoided so that analysis can be performed quickly on the updated data. In some time-sensitive scenarios, such as fraud detection, early analysis results can avoid losses.
Expressiveness. Graph data processing tasks are diverse, such as graph traversal, graph algorithms, graph learning, etc. Therefore, sufficient graph representation capabilities are needed to be able to represent different graph tasks efficiently.
What is GART?¶
GART is a graph extension that includes an interface to an RDBMS and a dynamic graph store for online graph computation.
There is a need to utilize graph data flexibly without altering the existing relational database system. Additionally, the issue of transparency arises, where users should not need to be concerned with the intricacies of graph data storage or the process of maintaining data consistency between relational and graph data stores.
To meet this requirement, GART has been developed—an in-memory system tailored for real-time, online graph computation. GART enables users to work with graph data effectively, ensuring that the graph representation remains current and in sync with the traditional relational data without direct user intervention for data synchronization.
GART uses transactional logs (e.g., binlog) to capture data changes, then recovers data changes into fresh graph data in real time. GART integrates graph computation engines (e.g. GraphScope, NetworkX) to support efficient graph computation processing. The workflow of GART is shown below.
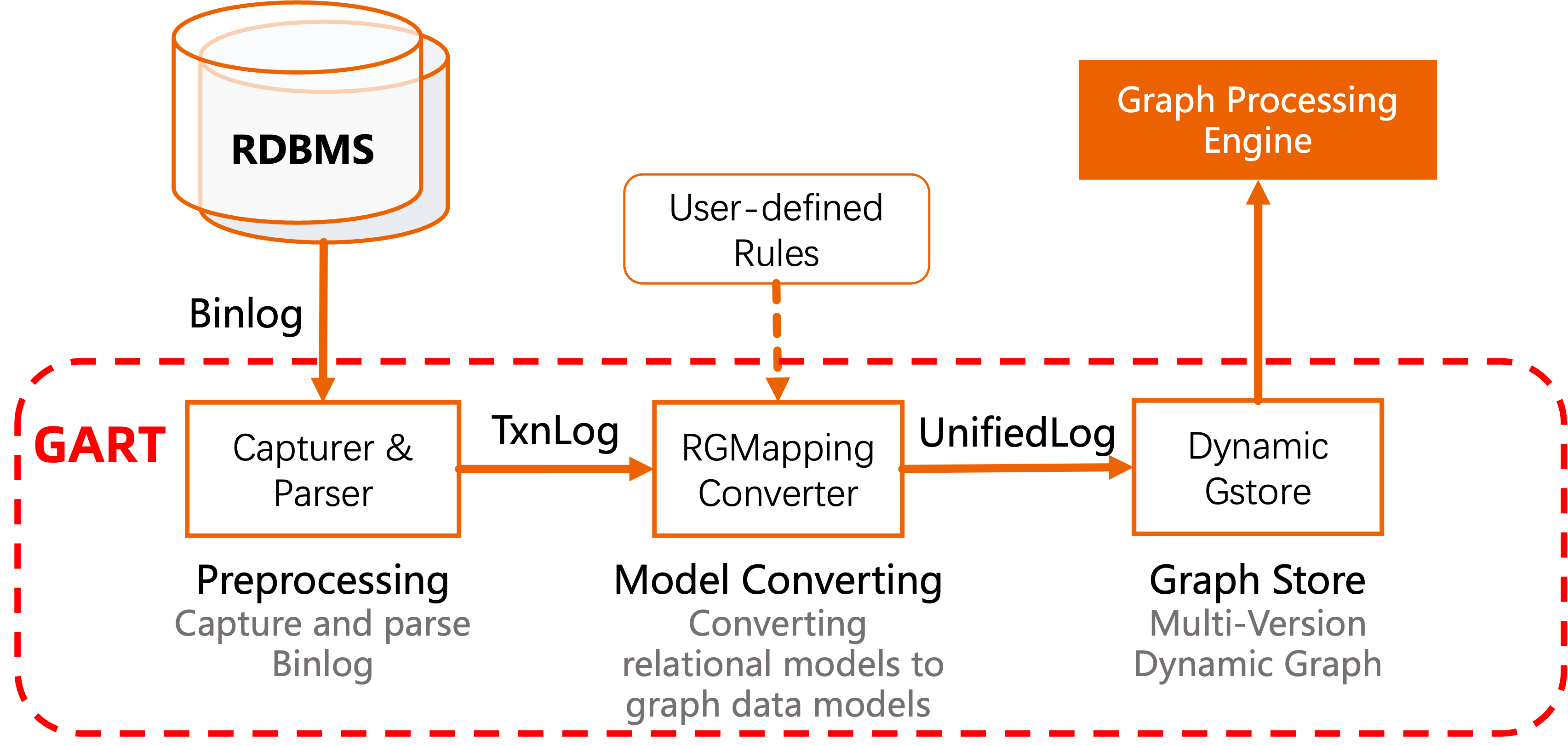
GART captures the data changes in different (relational) data sources (e.g., database systems, streaming systems) and converts them to graph data according to user-defined rules.
Features¶
Transparent Data Model Conversion¶
To adapt to rich workload flexibility, GART proposes transparent data model conversion by graph extraction interfaces, which define rules of relational-graph mapping. During the use of GART, data changes from relational databases are converted into graph data updates based on user-defined model mapping rules (RGMapping). GART provides a set of interfaces for DBAs to define data model conversion rules, which can be compatible with SQL/PGQ DDL.
We provide a sample definition file called RGMappings.
Efficient Dynamic Graph Storage¶
To ensure the performance of graph computation, GART proposes an efficient dynamic graph storage with good locality that stems from key insights into online graph computation workloads, including:
an efficient and mutable compressed sparse row (CSR) representation to guarantee the locality of scanning edges;
a coarse-grained MVCC to reduce the temporal and spatial overhead of versioning;
flexible property storage to efficiently run various graph computation workloads.
Service-Oriented Deployment Model¶
GART acts as a service to synchronize database changes to the graph store. When pulled up as a service on its own, users can try out the full power of GART and different graph computation engines on the graph store. At the same time, GART also provides a front-end, used as a database plug-in, currently supported as a PostgreSQL extension. Users can invoke GART’s functions in the database client, such as RGMapping definitions, graph computation on the graph store, etc.
Limitations¶
GART is still in the early stages of development, and there are some limitations:
GART currently only supports PostgreSQL and MySQL as the relational database.
GART currently only supports GraphScope and NetworkX as the graph computation engine.